“What we want is a machine that can learn from experience.”
– Alan Turing, 1947
Only a few technologies can be used in almost all industries and machine learning is one of them. It is revolutionizing the way business owners sustain the high user engagement rate and sales. From mining to health-care, logistics, robotics, human resource, all major industries have witnessed major changes in crucial business processes since the inspection of machine learning.
There is one industry which has been witnessing changes beyond one’s expectation. Yes, we are talking about the mobile apps industry. With machine learning, mobile apps become smart and offer personalized user experience to users. A machine learning-enabled mobile app analyzes user behavior and treats him accordingly.
However, actualizing machine learning-enabled mobile app is not as easy as pie. There are many parameters which a developer should take care of. Major parameters are machine learning module, machine learning algorithms and dataset on which a machine learning module is trained using a machine learning algorithm. If it sounds confusing, hold on. We will discuss everything about machine learning algorithms, machine learning modules, and datasets in this blog. We will also discuss the benefits of machine learning-enabled app and how using machine learning algorithms, modules, and dataset, one can develop a machine learning-enabled app. But before all of this, let’s first understand the concept of machine learning with an example.
What is machine learning?
Keeping this really easy for you!
According to Wikipedia, “Machine learning is the scientific study of the algorithms and statistical models that computer system uses to perform a specific task without human interaction.”
Let’s understand this definition word by word.
Statistical model and machine learning algorithms are the major two highlighted parts in the definition. With a machine learning algorithm which is nothing but a series of commands, a statistical model comes to action. It processes a lot of numeric as well as many other types of data and uses this output or learning to solve a problem automatically. The best part of machine learning algorithms and statistical models are that they both work together and help each other to evolve with time and data.
Generally, the statistical model gives data as input to a machine learning algorithm. It then finds meaningful relationships between different data attributes, makes rules and gives it back to statistical model. These rules are used by statistical model as input to solve a problem or to perform a task.
Let’s understand the concept of machine learning with an example.
Assume a football player. Throughout his career, his mind has collected many data of goalkeeper’s leg movement and his relevant next move. And based on this collected data, his mind has made so many rules, i.e if a leg of goal-keeper moves left, he would jump right. So, now while playing football, his mind takes the leg-movement of the goal-keeper as input and compares it with rules. If it finds the similarity, it simply predicts the leg movement of the goalkeeper.
Here, rules are made using data and machine learning algorithms (this is called data training). And these rules are used to solve a problem automatically. (in our example, the problem was leg movement-based prediction.)
So, now when you know the basics of machine learning, let’s wrap our minds around the benefits it offers to mobile app owners and users.
Use of machine learning in mobile apps
The reason why machine learning is being used in many industries is that it offers many benefits for each industry. Talking about the mobile apps industry, a properly accommodated machine learning technology can let app owners derive many financial benefits. These benefits are,
● Personalized content delivery
Offering personalized content is the key to acquiring more users and keeping user engagement rate high. If a user is interested in watching travelling content and the mobile app keeps showing him technology content, he will get annoyed and uninstall the app.
You can address this issue in two ways. You can either ask the user to add his interest or you can employ machine learning to analyze its usage patterns and predict his interest.
The first option seems really easy. But it is an ineffective method as an interest of users relies on many factors such as age, social background, education, location, etc. And because of this many factors, the user’s interest gets changed quite often.
On the other hand, the machine learning module which takes all important factors into account and understands the behaviour of the users, precisely. Using many robust algorithms, it builds a prediction model and predicts the user interest with the highest ever accuracy. And if the prediction model detects a single change in user behaviour, it changes the prediction which is not possible if we ask users to add their interest manually.
All popular entertainment apps, news app, and e-commerce apps are working on the same principle.
● Real-time image processing
Recently, image processing has become a very solid part of mobile apps. It is used to detect the identity of users and apply several fun filters on the face of users. Without the machine learning technology, it has never been possible to track the facial parts of users and verify the identity of him. Specific app module which is trained using machine learning algorithms and datasets scans the human face and discovers different parts of the face. App module gives this as input to another module which is responsible for applying filters on those facial parts. Snapchat is the most popular app which is processing images using machine learning.
● Chatbots
App users always raise queries and customer executives always goof-up those queries. Amid such a situation, a chatbot is the best way to provide pleasant customer service to the users. A chatbot is nothing but a simple program which acts on data. It takes user query as the input, compares it with already made rules and gives the most satisfying reply to the users.
● Real-time cyber-attack identification
Almost every-time, a cyberattack either on the mobile phone or on the server is identified after its occurrence. But what if we develop a program (for server) or mobile app (for mobile phones) , which scans every incoming package, compares it with rules and alerts the admin if it finds any malicious package, all in real-time? Yes, it is possible with a machine learning algorithm, Genetic Algorithm and a data-set called KDD Cup dataset. But we will talk more about this benefit of the machine learning at the end of the blog, with a comprehensive tutorial.
Top mobile apps working on the machine learning
Following is the list of top mobile apps which are working on machine learning.
1) Netflix
Purpose of ML: Classification and for personalized content delivery.
ML Algorithms: Linear Regression and Logistic Regression
2) Tinder
Purpose of ML: To find a precise match
ML Algorithms: Undisclosed
3) Google Maps
Purpose of ML: To predict parking difficulty at the destination
ML algorithms: Undisclosed but it relies highly on the public data
4) Dango
Purpose of the ML: To suggest the emoji based on what you are typing.
ML algorithms: Undisclosed, But it actually does not use ML. It using DL (deep learning) which is a subset of the ML and AI.
5) Snapchat
Purpose of the ML: For facial tracking
ML algorithm: Custom facial tracking algorithm which works on machine learning
How to apply machine learning on mobile apps?
Applying machine learning on mobile apps or developing machine learning-enabled mobile apps is easy only if you do it in the right steps. As we have discussed, machine learning module, machine learning algorithms and datasets are the major components to actualize the machine learning-enabled mobile app. To end up achieving the highest-ever success rate, you can follow the following steps.
- Identify the purpose behind integrating machine learning module in the app. Because purpose tells you about suitable machine learning algorithm.
- Choose a machine learning algorithm which justifies your purpose in the best possible way. For instance, if your purpose is classification, opt for Naive Bayes classifier algorithm.
- Once you choose the suitable ML algorithm, your next step is finding a reliable data-set. You need dataset because machine learning algorithms only work with data; they use datasets to make rules. You can use your own collected data or you can download the online available datasets. But make sure your selected dataset has enough data.
- Once you successfully collect dataset and machine learning algorithm, your next step would be writing a code which is generally considered as the machine learning module. This code includes the business logic of the ML algorithm. Just because of this code, the ML algorithm processes the data of the datasets and makes the rules. This whole operation is called ‘data training.’
- In the last step, you are required to develop an app module which is responsible for solving problems or predicting future using the rules.
So, now when you know that machine learning algorithms and datasets are vitally important to develop machine learning-enabled mobile app, let me reveal top 3 machine learning algorithms and top 5 datasets with their properties and uses.
Top machine learning algorithms for developing mobile apps
There are a lot of machine learning algorithms available and you can customize all of them according to your need. Moreover, machine learning algorithms learn by themselves with new data. Meaning, they need really less maintenance and human interaction.
Following are the top machine learning algorithms for different purposes of mobile apps.
● Naive Bayes Classifier Algorithm
If you are developing a news app, an app like Pinterest or any other apps in which classifying the screen content such as images and documents is the fundamental requirement, you have to train data using Naive Bayes Classifier Algorithm. It does not only classify the content, but it places the content in the relevant category.
● K Means Clustering Algorithm
K means clustering is another very popular algorithm for classification. But compared to the Naive Bayes classifier algorithm, K means clustering algorithm has higher efficiency and processes a large number of data. And thus, it is being mostly used in e-commerce apps. It scans the inventory, identifies the top categories, creates a cluster for each category, puts items into relevant clusters and shows Apple iPhone rather than apple fruit when a user searches for Apple!
● linear regression algorithm
Like user app, admin panel should also be equipped with machine learning-enabled modules and one very useful admin panel module is forecasting.
If an admin panel has such a module, admin can know the effect of any changes in demand and sales before actually imposing any change. For that linear regression algorithm is being used. It studies the historic data as well as real-time data and calculates the dependency of an attribute on other attributes. With calculated dependency, it predicts the change in the value of an attribute, if you change the value of other attributes. Big companies like Target and Walmart depend on this algorithm to make changes in the price of a product.
Top useful datasets to develop machine learning-enabled mobile app
Following are the verified datasets which are holding enough data to train the machine learning models.
● QuandI
QuandI is the dataset storing financial and economical data. It contains the data of the world’s top hedge funds, asset managers and investment banks. Using this dataset, you can train the machine learning model for the FinTech apps.
● ImageNet
ImageNet dataset is the best choice to train a model for satisfying image processing needs. This dataset stores 100000 phrases and 1000 images for each phrase into Worldnet hierarchy.
● Chicago taxi trips data
If you want to develop a taxi app which runs on the machine learning technology, Chicago taxi trips dataset will do justice. This dataset stores data from 2013 to present. All details of the trips including distance and time are making it very useful dataset for developing driver allocation and fare calculation modules.
● FIFA World Cup 2018
To develop a machine learning-enabled sports app, you can derive many benefits from FIFA World Cup 2018 data. It is the official data, released by FIFA.
● KDD Cup
If you need to train your model for the cybersecurity purpose, there isn’t any other good dataset available than KDD Cup. It contains internet packages data with the value of each attribute, type of attacks and what was the value of the attributes at the time of attack.
So far, we have talked about every important concept of machine learning and way to develop machine learning-enabled mobile app. But before concluding this blog, I would like to present an example. This example will solve every question related to machine learning if you still living with one. In this example, I will show you how with a machine learning algorithm and dataset, we can develop an Intrusion Detection App which identifies harmful intruder (virus), trying to enter the mobile phone.
Machine Learning in Action – Developing Intrusion Detection App using Genetic Algorithm and KDD dataset
To make this understanding very rational, I will share the details of each component of the Intrusion Detection App separately. But before that, it is worth mentioning that IDA (Intrusion Detection App) monitors each and every incoming package and compares the package and its values with the rules to identify the malicious packages and genius packages. If it identifies the malicious package, it alerts the user or drops the package by itself.
IDA is made out of a major two modules. One is IDA itself and other is rule engine. Rule engine makes rules using dataset and algorithm and IDA compares incoming packages with rules to identify the attack. In our case, we take the KDD Cup as dataset and genetic algorithm as a machine learning algorithm.
- KDD cup dataset
As discussed, KDD Cup dataset stores very important data of packages and its attributes with values. Following are the attributes of the packages.

- Genetic Algorithm
Now, we apply this dataset to a genetic algorithm which is the part of the rule engine. The genetic algorithm processes this dataset and finds meaningful relationships between attack types and attribute value. It then makes rules based on this outcome. Rules have a fixed ‘If…then’ format but with different values, If Duration = “3”, Protocol Type = “5”, service = “1”, ……..” then Attack type = “DOS”. Rules engine shares these rules with IDA which is responsible for capturing each entering package, comparing it with the rules and issuing the alert to the user if it finds any uncommon similarity between rules and entering package. But one question is still unanswered: how does the genetic algorithm make the rules? To understand it, we need to understand the working method of the genetic algorithm.
The genetic algorithm takes KDD dataset as input and generates random values which are called population. It now compares the dataset values of a row and population values of a row with each other and based on the same values presented in both rows, it calculates the fitness function of each row of the KDD dataset. Fitness function is nothing but a number which tells how near a row is to the optimal solution. It then discards the rows of the dataset which are having values of fitness function below a certain value. Remaining rows undergo two more operations, Mutation and Crossover. In Crossover, the values of two rows get interchanged. And in Mutation, the values of one single row get interchanged.
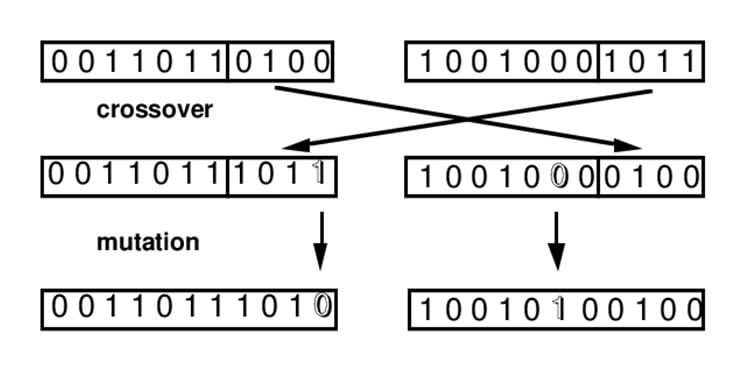
The genetic algorithm takes the output of the Mutation operation as the input for the second round. In the second round also, it follows the same path. It generates the population, finds the fitness function, discards rows with low fitness function, performs Crossover and Mutation on remaining rows, starts round three and so on. After a certain round (maybe more than 100), only those rows with the highest fitness function are left. And this is considered as the solution to our problem. The algorithm makes rules by taking the value of each attribute and attribute names and deliver those rules to IDA for implementation.
Conclusion
Dear Alan Turing, We made it!
Vishal Virani is a Founder and CEO of Coruscate Solutions, a leading taxi app development company. He enjoys writing about the vital role of mobile apps for different industries, custom web development, and the latest technology trends.